
Physicists Explore The Rise And Fall Of Words
Scientific techniques show promise for future linguistics research.
Image
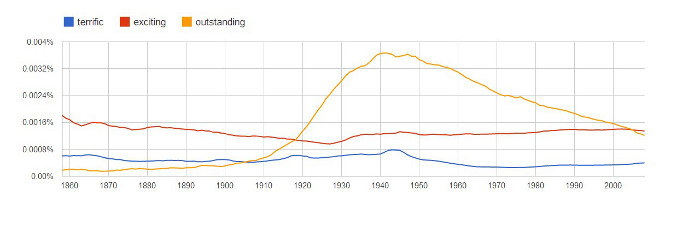
The use of terrific (blue), exciting (red), and outstanding (gold) from 1858-2008.
Media credits
Google Ngram Viewer: http://bit.ly/VCFrnd
(ISNS) -- Every year the Oxford English Dictionary expands, incorporating freshly coined terms such as "bromance," "staycation" or "frenemy." However, a recent analysis has found that as a language grows over time, it becomes more set in its ways. New words are always being added, according to this study, but few become widely used and part of the standard vocabulary.
"There are a lot of new hip words that are sort of popping out, but the popularity and the lifespan of these words are very short," said Matjaz Perc, a physics professor at the University of Maribor in Slovenia and one of the authors of the paper. "Our study shows that we don't really need them, so the mileage that we get out of them is very low compared to other words."
Google has scanned more than 20 million books, or approximately 4 percent of all books ever published in nine major languages, and made them accessible to anyone with an Internet connection. It's this online database that the researchers studied. The results were published in Nature Scientific Reports.
The Google database includes books written in the 1500s, but the team limited its research to the last two centuries. They tracked the proliferation of words throughout the library using Google's Ngram viewer to study the growth and usage patterns of words in a language.
"This Google Books Project has provided this huge platform to do this all at once," said Alex Petersen, a physicist at the IMT Lucca Institute for Advanced Studies in Italy, and lead author of the paper.
The team says that the "core lexicon" of the English language is made up of about 30,000 words that show up more frequently than one word in a million. There is also a body 100 times as large, of rarely used words, which applies to the vast majority of new words. Some of the few that jumped from the rarely used category into the core lexicon in recent years have been words like "email" or "Google." However these are the exception, not the rule.
"We're not coming up with new color names or descriptions for things we've already established," Petersen said. "A lot of the new words that we see are related to computers."
At the beginning of the 19th century, fewer new words were introduced than now, but their popularity changed dramatically from year to year. A word like "paper" might be in the top thousand most used words one year, and then drop off in use for a while, only to return in popularity years later.
"All things being equal, you would expect that each word would have the same popularity from year to year," said Joel Tenenbaum, a physicist at Boston University and a coauthor of the paper.
The scientists found that as the vocabulary of a language grew, a word's popularity would change less and less, until the modern era where the most popular words have remained constant for decades. It wasn't just English that "cooled" as it grew.
"In the paper we find this overwhelming trend across all languages," Petersen said.
To linguists, many of the conclusions reached by the researchers were known within the community.
"They’ve done some of the largest scale work that anyone has ever done," said Bill Kretzschmar, a linguist at the University of Georgia. However, he called their results underwhelming. "For every million words you add after the first couple, you don't get much return from that, and we knew that already."
Petersen responded that theirs was the first attempt to quantify exactly how much a language "cools" as it expands.
Kretzschmar said that he was glad that physicists and mathematicians were starting to get interested in linguistics. He said that the statistical techniques employed by the researchers could potentially bring new insights to the field.
"They bring models and methods that I don’t have," Kretzschmar said. "I think this is an important movement in the study of language."
He added that the vastness of the Google library means that nonfiction books, fiction, poetry and journal articles were all brought together into the same database. This poses a problem because these different forms of written communication vary dramatically in their use of language, such as in their level of formality, making direct comparisons difficult.
"Because there is a similar mix from year to year, we're not comparing apples to oranges. We're comparing a basket of apples and oranges to another basket of comparable fractions of apples and oranges," Petersen said. Google does break some of their English texts into subcategories, like British English, American English and English Fiction. "We found the same patterns independent of which Google dataset we used.”
Kretzschmar also faulted Google's metadata as sometimes inaccurate. It includes information about the scanned books such as their publication dates, author and publisher. In addition, computers often misidentify letters when interpreting a scanned page. Google will read it as a new word, though really it's just a misspelling.
Petersen said that was a known flaw in their work, and they were working on an improved way to prune out errors.
Mike Lucibella is a contributing writer to Inside Science News Service.
Filed under