
The Superconducting Dance Of Electron Pairs

(Inside Science) -- Even now, three decades after Marty McFly first mounted a hoverboard in Back to the Future's vision of 2015, they are still the talk of science fiction, as shown by the stories and videos that can be found online. However, some scientists from Brookhaven National Lab in New York might have just brought us a little closer to making that dream a reality.
Back in the 1980s when Doc Brown was busy transforming a DeLorean into a time machine, real-life scientists had just discovered that some copper containing materials called cuprates had zero electrical resistance at record breaking temperatures. These materials are now known as high temperature superconductors due to their ability to retain superconductivity at temperatures above the still frigid boiling point of liquid nitrogen (minus 321 degrees F) -- previously thought to be impossible.
When a material is in its superconducting state, it also has the ability to expel external magnetic fields. It can also generate super intense magnetic fields due to the ability to sustain large electric currents without overheating.
Today you can find superconductors at work inside MRI and NMR machines in hospitals as well as the tunnels of the Large Hadron Collider near Geneva, Switzerland. However, for these superconductors to work, we still need to keep them cool with liquid nitrogen -- gallons upon gallons of it. If we decided to try to harness their power on a larger scale, such as for an international power grid or an affordable mag-lev train system, the cooling cost will go through the roof. So ultimately we need something that can superconduct at "real-world" temperatures.
Even after spending decades trying to unravel the mystery behind high temperature superconductivity, scientists still don't quite understand why superconductivity occurs in certain materials and why it stops at a certain temperature.
"In almost all unconventional superconductors, the classical theory of metals and superconductivity breaks down, so we have been deprived of a foundation for our understanding," said Greg MacDougall, a physicist at the University of Illinois at Urbana-Champaign, "and until we develop a fundamental understanding of the mechanism driving the superconducting state, the next high temperature superconductor can always only be found through serendipity."
Thanks to the recent research paper by the team from Brookhaven, published in the journal Nature, we might have finally caught a glimpse of light.
Ivan Bozovic, the physicist leading the research effort at Brookhaven, has been studying the cuprates ever since they were first discovered in the 1980s.
"High temperature superconductivity is arguably the most important problem in condensed matter physics," said Bozovic as he explained his motivation behind the lifelong effort.
"As long as this problem is not solved, I'm not going to quit," he added.
To understand the discovery, you first need to understand the vital role of electron pairs in superconductivity. By pairing up together, the electrons are able to overcome any electrical resistance, making the material a superconductor. In short -- no electron pairs, no superconductivity.
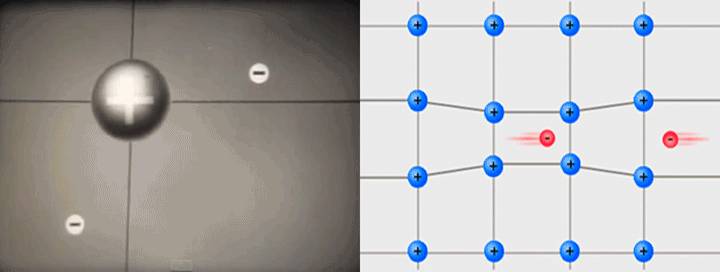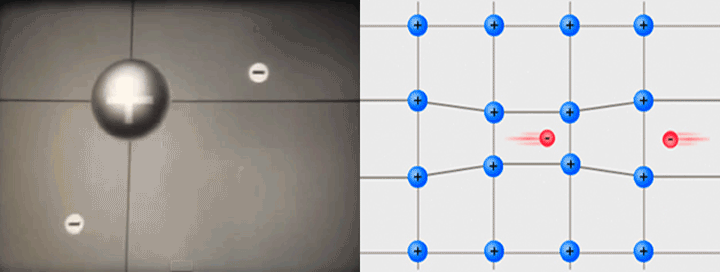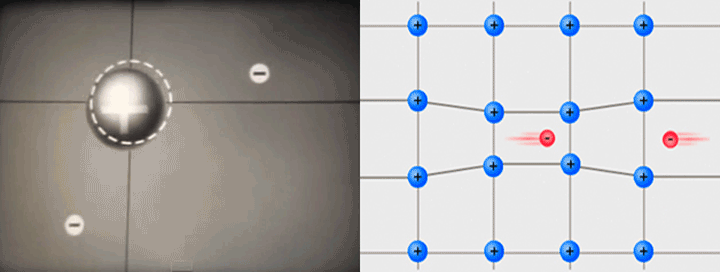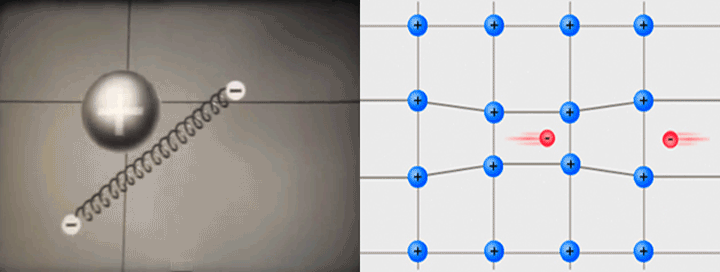
Inside a superconductor, electrons (-) that normally repel each other can pair up through a middleman - protons (+).
Gif on the left generated from video by Alik Laliashvili, Standard Youtube License
Image on the right by Tem3psu, CC BY-SA 4.0, Wikimedia Commons
Now think of the electron pairs as couples on a dance floor. When the floor gets too hot, the couples start to break up. Bozovic's team discovered that when more of these "couples" are crammed onto the dance floor, they tend to stay together up to higher temperatures.
Intuitive or not, the observation seems straightforward enough, so why haven't scientists looked at this until now? Well, they have, or at least, Bozovic's team has, for more than 10 years. The current revelation was only possible after rigorous testing on more than 2,000 variations of a cuprate called LSCO, which is made up of lanthanum, strontium, copper and oxygen.
"Imagine you have just discovered the cure for cancer, and people ask you 'How many patients have you tested on?' If you say 'three,' they will drop dead laughing," Bozovic said.
To prove that a cancer treatment is effective, it would need to be tested on many different people in a carefully controlled clinical trial -- for different kinds of cancer, during different stages of the cancer, and so on. Just like the human body, complex materials like cuprates contain mountains of variables that need to be controlled and monitored. The goal is to find and define a pattern that cuts through all the noises in the data, and to develop a consistent theory amidst a world of variables.
So what's next? The obvious next step is to test the findings on other cuprates and perhaps even other superconductors.
"Any universal behavior we can find, that transcends material families would be huge. It will help us understand the phenomenology in a larger context," said MacDougall, "This sort of empirical knowledge is what you need to develop a theory."
Another route is to explore methods to manipulate the electron pairs' density, now that scientists know its relationship to the temperature limit. Either way, it seems likely that this discovery will breathe new life into the hunt for the holy grail that is room temperature superconductivity.
After all, in the dawn of superconductivity, resistance is futile.
*Sources for the images used in the article body: Electron pair animation, Electron pair inside a crystal lattice.
